全球清廉指数是个啥玩意
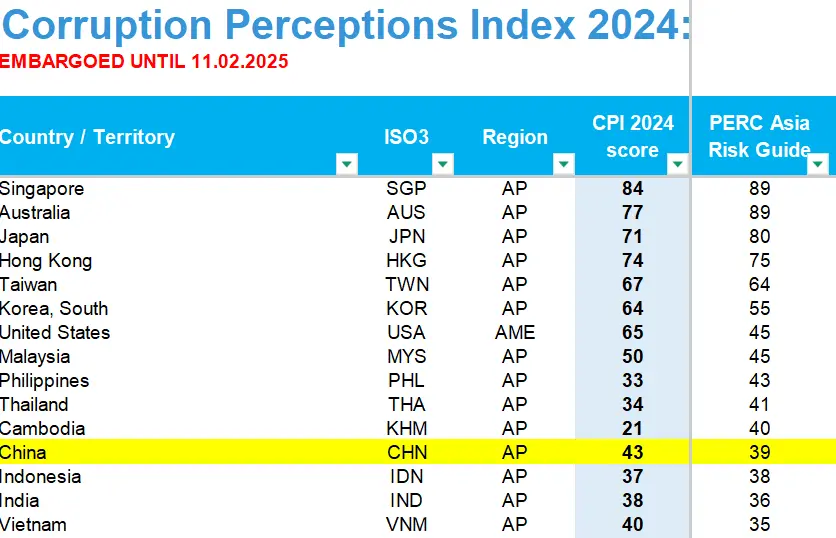
今天在微信群看到有人转发全球清廉指数排名,中国位居全球 76 名,跟摩尔多瓦、所罗门群岛一个水平,只比印度多 5 分,而比欧洲低了四五十分。直觉告诉我,这个指数应该有点问题,中国这些年一直在认真对付深层次腐败,没道理排名会下降这么多。结果一查,发现这玩意真是惊掉下巴。
所谓全球清廉指数实质上就是个二手指数
在透明国际 官网 上,对于全球清廉指数(CPI)是这么描述的:
The Corruption Perceptions Index scores 180 countries and territories according to the levels of public-sector corruption perceived by experts and businesspeople. It relies on 13 independent data sources and uses a scale of zero to 100, where zero is highly corrupt and 100 is very clean.
但实际上,打开报告后发现,他的研究方法是:
The CPI 2024 is calculated using 13 different data sources from 12 different institutions that capture perceptions of corruption within the past two years.

对比发现,报告中写的是清廉指数依据13个独立数据源,通过标准差和方差这种纯数学方法计算得出。连计分权重都没有,实质就是选取一堆所谓国际排名进行综合,得出最终的“清廉指数”,毫无疑问就是个“二手指数”。
移花接木的指数介绍
继续看上边两段描述。在报告中讲的研究方法是:依据13个独立数据源计算得出清廉指数,从而为商人和国家、专家提供了对公共部门腐败程度的看法。
The Corruption Perceptions Index (CPI) aggregates data from a number of different sources that provide perceptions among businesspeople and country experts of the level of corruption in the public sector.
而在报告介绍页面,讲的研究方法是:根据专家和商人对公共部门的腐败认知程度,腐败认知指数对180个国家和地区进行了评分。它依赖于13个独立的数据源,并使用0到100的规模,其中0是高度腐败的,100是非常干净的。

两者差异在于,报告介绍中“专家和商人对公共部门的腐败认知程度”是报告的排名依据;而报告内容中汇总13个独立数据源而成的二手指数是“为商人和国家、专家提供了对公共部门腐败程度的看法”。
报告介绍明显在混淆视听,意图让观众误以为这个清廉指数是根据专家和商人的调查得出的结论,而实际上并不是。
精心设计的计算陷阱
清廉指数所用的计算方法是纯数学的,它通过从每个国家的分数中减去基准年每个来源的平均值,然后除以基准年该来源的标准差来实现的。并且,这个减法是使用标准化分数将其乘以2012年(20)的CPI标准差值,再加上2012年的平均值(45),转换为CPI量表。
这种算法本身倒没什么问题,但仔细查看 原始评分数据 可以发现,清廉指数所计算的13个数据源中,大部分国家都只有 7-8 项数据,甚至不少国家只有 3-5 项数据。
在这种情况下,使用前边这种数学计算,很容易放大最终得分差距,制造计算陷阱。
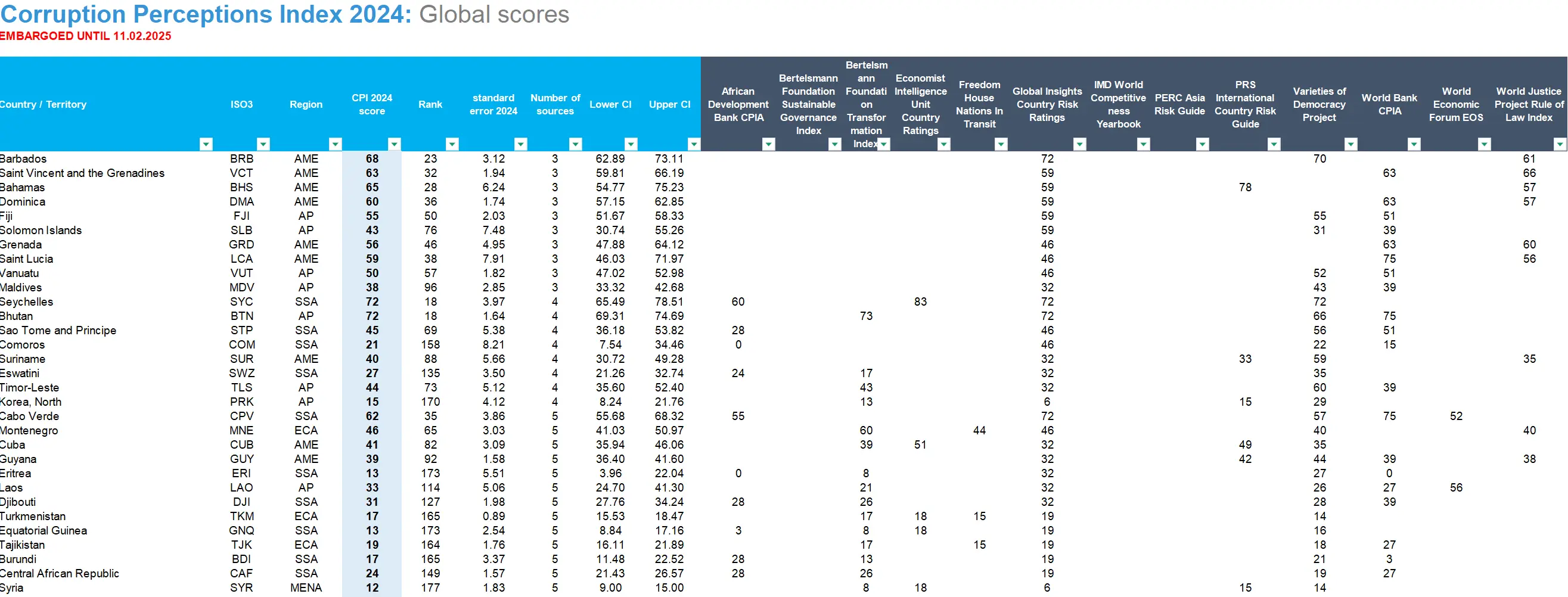
- 放大差异:CPI的标准化基于 基线年的分布(如2012年均值和标准差),但若某些国家在基线年已处于极端位置(如极高或极低分),后续年份的标准化会持续放大其差异。
- 固定参数限制:CPI强制通过
z×20+45映射到0-100,但若原始数据中存在极端z值(如z=3),转换后分数会达到105分(超范围),实际可能截断为100分。这会人为制造“天花板效应”,使少数高分国家集中在90+,而低分国家被压制在0附近。 - 覆盖偏向性:部分数据源(如国际组织报告)倾向于覆盖治理水平较高或受关注度高的国家,导致对这些国家的评分更密集,而边缘国家的数据可能依赖少量粗糙指标,误差被放大。
- 示例:
假设2012年国家A的原始分为90分(基线年均值=60,标准差=15),则其z-score=2 → CPI=2×20+45=85分;
若2020年国家A的原始分仍为90分,但当年其他国家的平均分下降至50分(标准差仍为15),其z-score=2.67 → CPI=2.67×20+45=98.4分。 - 结果:即使原始分未变,发达国家会因为全球平均CPI分数下降而被“放大”到更高。
精心挑选的白左意识形态数据
我认真查询了一遍清廉指数所引用的 13 个所谓的独立数据源。结果一看,其中 9 个都能轻松查到**美国国际开发署(USAID)**的资助记录,剩下 4 个里边,有两个疑似为 USAID 资助,只有标普评级和瑞士洛桑国际管理学院两个项目暂未查到相关信息。如此大的白左含量,几乎可以毫不客气的说,透明国际这个所谓清廉指数,就是个纯纯的的白左意识形态评级。特别是其中臭名昭著的自由之家、经济学人等反华组织,就差把反华两字贴在脑门上了。
1. African Development Bank Country Policy and Institutional Assessment (CPIA) (疑似USAID资助)
- 发布机构:非洲开发银行(African Development Bank, AfDB)
- 主要内容:
评估非洲国家的政策质量和制度效能,包括 经济管理、公共部门治理、社会包容、环境可持续性 等维度,重点关注低收入国家的治理能力。 - 特点:覆盖范围限于非洲国家,为国际援助分配提供参考。
2. Bertelsmann Foundation Sustainable Governance Index (SGI) (USAID资助)
- 发布机构:贝塔斯曼基金会(Bertelsmann Foundation,德国)
- 主要内容:
分析OECD和部分欧盟国家的 治理可持续性,涵盖 政策绩效、民主质量、国际合作 三大领域,强调长期治理能力。 - 特点:聚焦西方治理模式,数据基于专家评估。
3. Bertelsmann Foundation Transformation Index (BTI) (USAID资助)
- 发布机构:贝塔斯曼基金会(Bertelsmann Foundation)
- 主要内容:
评估全球发展中国家和转型国家的 民主建设、市场经济、政治稳定性,关注国家转型过程中的挑战与进展。 - 特点:覆盖约140个国家,每两年更新一次,结合定量与定性分析。
4. Economist Intelligence Unit (EIU) Country Ratings (USAID资助)
- 发布机构:经济学人智库(Economist Intelligence Unit, EIU)
- 主要内容:
提供全球国家的 政治风险、经济政策、营商环境和主权信用风险 评级,侧重宏观经济和地缘政治稳定性。 - 特点:被广泛用于跨国投资和风险评估,数据偏向商业视角。
5. Freedom House Nations in Transit (USAID资助)
- 发布机构:自由之家(Freedom House,美国非政府组织,2019年因在香港修例风波中表现恶劣被中国列入制裁名单)
- 主要内容:
监测中东欧、中亚和后苏联国家的 民主化进程,评估 选举公正性、公民自由、反腐败、司法独立 等指标。 - 特点:聚焦“转型国家”,立场鲜明支持西方民主标准。
6. Global Insights Country Risk Ratings
- 发布机构:IHS Markit(现为Global Insights,隶属标普全球)
- 主要内容:
评估全球国家的 政治、经济、安全风险,侧重短期风险预警(如冲突、政策突变)对商业活动的影响。 - 特点:服务于企业和投资者,数据更新频率高。
7. IMD World Competitiveness Yearbook
- 发布机构:瑞士洛桑国际管理学院(IMD)
- 主要内容:
排名全球经济体 竞争力,涵盖 经济表现、政府效率、商业效率、基础设施 四大维度,包含大量硬数据(如GDP、失业率)。 - 特点:数据来源多样,结合统计数据和高管问卷调查。
8. PERC Asia Risk Guide (USAID资助)
- 发布机构:政治与经济风险咨询公司(Political & Economic Risk Consultancy, PERC,总部香港)
- 主要内容:
评估亚洲和大洋洲国家的 商业风险,包括 腐败、政策透明度、法治环境、官僚效率。 - 特点:聚焦亚太地区,数据基于外籍企业高管的问卷调查。

9. PRS International Country Risk Guide (USAID资助)
- 发布机构:政治风险服务集团(Political Risk Services Group, PRS)
- 主要内容:
量化全球国家的 政治、经济、金融风险,预测政权稳定性、征用风险、货币危机等。 - 特点:提供风险评分和排名,常用于保险和跨国投资决策。
10. Varieties of Democracy Project (V-Dem) (USAID资助)
- 发布机构:哥德堡大学(瑞典)与圣母大学(美国)联合研究项目
- 主要内容:
提供全球最详细的 民主质量数据集,涵盖 选举民主、自由民主、参与式民主、协商民主 等多个维度。 - 特点:数据颗粒度极细(数百个指标),但部分指标依赖专家主观判断。
11. World Bank Country Policy and Institutional Assessment (CPIA) (疑似USAID资助)
- 发布机构:世界银行(World Bank)
- 主要内容:
评估发展中国家(主要受援国)的 政策与制度质量,包括 经济管理、结构改革、社会包容、公共部门治理。 - 特点:直接影响世界银行援助资金的分配,覆盖约80个国家。
12. World Economic Forum Executive Opinion Survey (EOS) (USAID资助)
- 发布机构:世界经济论坛(World Economic Forum, WEF)
- 主要内容:
通过全球企业高管的问卷调查,收集对各国 营商环境的感知,包括 基础设施和旅游、市场主体活力和能力、创新生态、人才与就业 等。 - 特点:数据被用于编制《全球竞争力报告》,反映商业精英视角。
13. World Justice Project Rule of Law Index (USAID资助)
- 发布机构:世界正义工程(World Justice Project, WJP,美国非营利组织)
- 主要内容:
衡量全球国家的 法治水平,涵盖 政府权力制衡、司法腐败、基本权利、刑事司法、民事司法 等子领域。 - 特点:数据来源包括公众问卷调查和法律专家评估,立场偏向自由法治观。

与腐败基本无关的数据源
我逐个查找了上边 13 个数据源的报告介绍和有关情况,发现实际上仅有 3 个数据源跟腐败有关系,其余均为民主、治理、法治等广义指标。而这 3 个包含了腐败问题的数据,一看也都是垃圾数源。
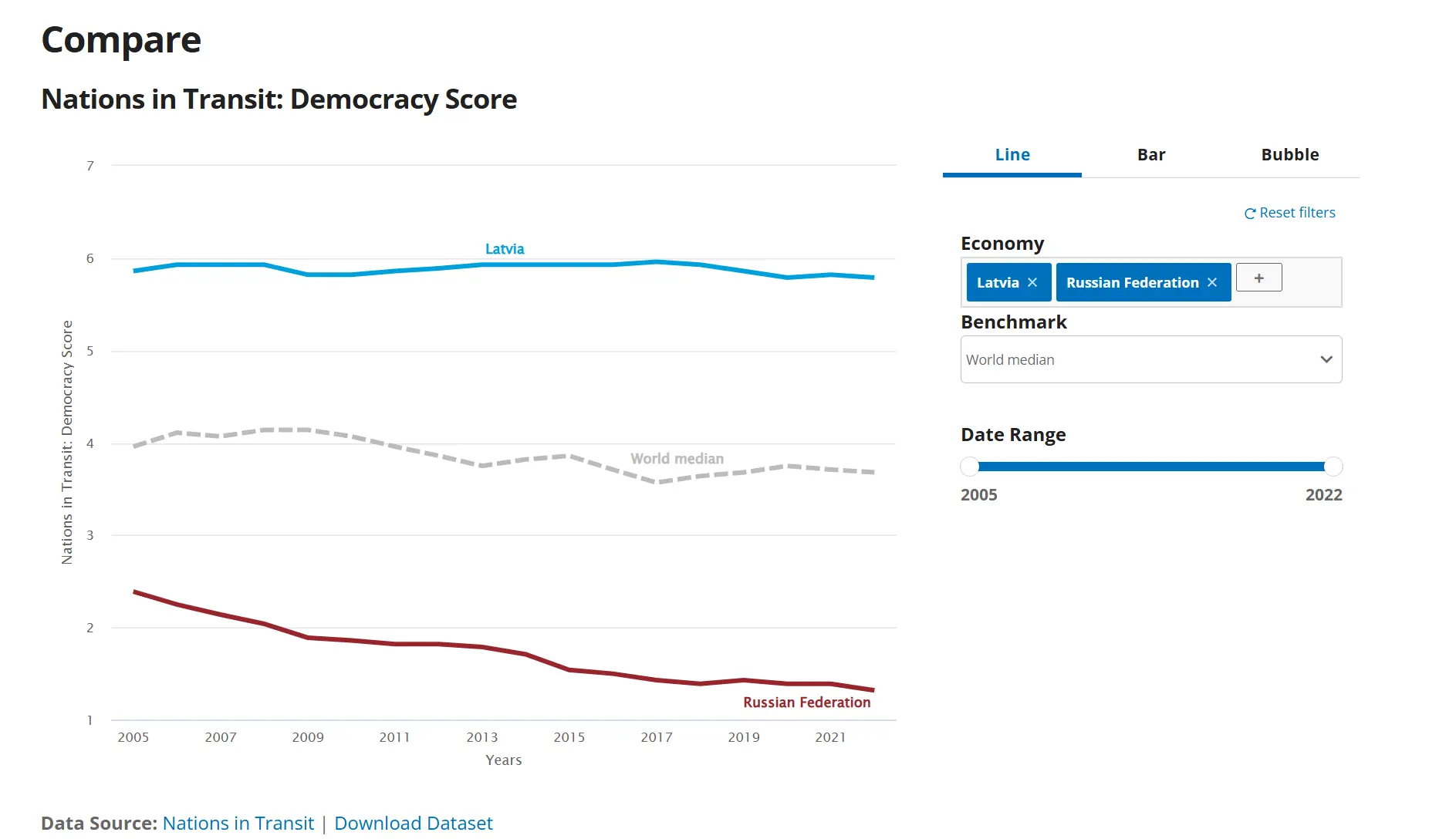
1. Freedom House Nations in Transit
- 这个自由之家的数据源,好在只列了东欧和苏联解体后的20多个国家,不然中国还真不知道黑成啥样。在这个数据源里边,俄罗斯毫无疑问被当作垫底角色,而波罗的海三小国都是最高分。事实上在世界银行营商环境报告评价中,俄罗斯这个苏联解体后的老大哥,反腐水平远超某些中亚国家。
2. PERC Asia Risk Guide
- 这个香港的 POLITICAL & ECONOMIC RISK CONSULTANCY LIMITED (政治和经济风险咨询有限公司)就是 USAID 豢养的反华机构。在它弄的腐败排名中只包含中国和周边15个国家地区。它给中国的清廉水平打了39分,比菲律宾、柬埔寨都低。但在世界银行营商环境报告中,中国商业贿赂查处效率是菲律宾的 3.2 倍。
3. World Justice Project Rule of Law Index
- 这个美国 NGO 搞的所谓“世界正义工程”,也是看起来很唬人,但一看排名,扯淡的很,它把中国排在95名,比蒙古、越南、印度、尼泊尔这些都低一二十个名次以上,一看就知道是咋回事。
但我还是重点看了下这个“世界正义工程”的报告,毕竟国内也有同行提出,要重视这个指数。 《中国人民大学助教孟涛:世界正义工程法治指数可借鉴》
问题是,这玩意真是越看越不对劲。这个报告数据都是通过一份 340 个问题的问卷调查得出来的(不得不说 NGO 牛逼,我读大学时在街头找人做 10 个题目问卷都觉得难上天,他们能搞出 340 道题目几十页的问卷),但是在中国居然只找了508人调查,连科索沃都有 1000 人,阿富汗都能找到 3000 人,结果他在中国就找了 508 人。
得出的结论也都是啼笑皆非:
- 在 142 个国家和地区中,中国人权保障排名倒数第三
- 劳动权利保障排名全球倒数第三
- 言论自由排名全球倒数第二
- 政府权力受非政府制约的约束排倒数第二
- 公民的生命权和人身安全权保障排名 125 位
- 民事、刑事司法受政府干预程度都排在 130 名以后
- 中国的腐败类型里边最严重的腐败是司法腐败
这种荒唐的结果,简直是想把中国各方面进步摁地上在捶。特别是其中公民的生命权和人身安全权保障那项,众所周知中国是世界最安全国家之一,在包括世界卫生组织、世界银行在列多边组织的各种相关统计指数中,中国都在全球遥遥领先,这他妈都能被他们排到跟南苏丹、索马里一个水平,不得不说美国 NGO 牛逼!!! USAID 这钱花的真值!!!
值得玩味的是,这个“世界正义工程”报告是我查了上边 13 个数据源,发现唯一有对“腐败”这一项单独列数据的。但透明国际在编制“清廉指数”时,毫无悬念的使用这个报告的总体排名数据。中国在“世界正义工程”总体排名,比其中“腐败”这一子项目的排名要低 40 多个名次。
纯意识形态操弄
在我第一次打开透明国际官网看到 2024 年全球清廉指数报告页面时,就感受到一股浓厚的西方白左意识形态之风。页面地址: 2024 Corruption Perceptions Index: Corruption is playing a devastating role in the climate crisis
当我们普通人还想着反腐主要是打贪官时,人家白左反腐的重点居然是为了应对气候危机,意图把气候问题政治化。

透明国际首席执行官 Maíra Martini 表示:
“我们必须紧急根除腐败,以免它完全破坏有意义的气候行动。政府和多边组织必须将反腐败措施纳入气候工作,以保护资金、重建信任并最大限度地发挥影响。今天,腐败力量不仅塑造而且经常支配政策并瓦解制衡——使记者、活动家和任何为平等和可持续性而战的人保持沉默。真正的气候韧性需要直接果断地应对这些威胁。世界各地的弱势群体迫切需要这项行动。
绿色和平国际执行主任 Mads Christensen 说:
“今年的分析再次表明,化石燃料腐败如何破坏气候努力,包括在美国。世界各地的社区都要求政府采取气候行动。但是,人们的声音一次又一次地被石油和天然气公司的腐败力量所抵消,这些公司从环境破坏中获利,他们利用数十亿美元试图压制批评者和活动家,购买电力,并拆除保护我们家庭和地球的保护措施。绿色和平组织和我们的盟友正面临来自管道巨头 Energy Transfer 的威胁,该公司正试图通过一场大规模的、似是而非的诉讼将我们从美国的地图上抹去。我们所有关心未来的人都有责任不惜一切代价站出来对抗这些企业恶霸。
在列举事例时,报告提出因为索马里的政府腐败,导致这些国家气候变化,从而对农业生产造成严重破坏,加剧了长达 30 年的冲突。相当于直接将气候议题与西方长期推广的民主自由那套挂钩上,这种操弄政治议题的能力,确实别出心裁、无出其右。

亚洲每年有 8.4 亿人行贿?
对一个国家的腐败情况进行评价,采用调查问卷这种模式并不是不行。
但这种调查,对问卷设计以及调查方法的设计有很高的要求,不是随便弄个调查就能得出结论的,起码要解决三个问题:
主观性与文化偏见的干扰
- 感知≠现实:问卷反映的是受访者的“主观判断”,而非实际腐败程度。
- 文化差异的误读:某些行为(如礼品文化、人情往来)在不同社会中被定义为“腐败”的阈值不同,但问卷设计可能强加西方标准。
样本代表性的难题
- 城乡差距:多数问卷依赖城市样本,可能忽略农村地区的腐败形式(如土地侵占、基层官僚勒索);
- 精英视角主导:专家问卷依赖学者、国际机构雇员等群体,其观点可能与普通民众脱节;
政治化风险
- 西方话语权渗透:问卷设计常隐含对“民主制度”“公民社会参与”的推崇,导致非西方治理模式(如中国注重党内监督)在指标中被系统性贬低。
- 国际博弈工具化:清廉指数可能被用于施压他国(如将低分国家与援助资金挂钩),而非纯粹学术评价。
但可惜,透明国际在这事情上,明显就是故意设局,处处透漏出造假嫌疑。
比如透明国际在搞“清廉指数”的同时,其实他第二重要的工作叫做 Global Corruption Barometer (全球腐败晴雨表调查)。
一打开这个 全球腐败晴雨表调查报告 又把我惊呆了。

该报告在介绍页面用特大字体显示:亚洲上一年度有 20% 的人行贿,总共 8.36 亿人。
吓得我赶紧下载数据看看到底咋回事。
这一看不要紧,看完整个人都懵逼。原始数据下载: GCB-2020-ASIA-FINAL
扯淡的行贿率计算
| 国家/地区 | 总体行贿率 | 公立学校 | 公立医院 | 办身份证照 | 用水用电 | 警察 | 警察局 | 政府机构 | 官员 | 议员 | 法官 | 不知道 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 日本 | 2 | 2 | 2 | 0 | 4 | 2 | 10 | 7 | 26 | 42 | 6 | 2 |
| 韩国 | 10 | 11 | 6 | 7 | 14 | 8 | 23 | 26 | 42 | 65 | 24 | 0 |
| 台湾 | 17 | 5 | 9 | 29 | 28 | 67 | 17 | 19 | 20 | 17 | 15 | 0 |
| 印度 | 39 | 22 | 24 | 41 | 32 | 42 | 46 | 41 | 46 | 42 | 20 | 3 |
| 中国 | 28 | 27 | 26 | 18 | 17 | 23 | 16 | 18 | 16 | 11 | 12 | 1 |
| 马来西亚 | 13 | 8 | 5 | 9 | 11 | 17 | 30 | 28 | 18 | 36 | 13 | 2 |
| 印度尼西亚 | 30 | 22 | 10 | 31 | 13 | 41 | 33 | 45 | 48 | 51 | 24 | 3 |
| 泰国 | 24 | 21 | 10 | 16 | 25 | 47 | 37 | 30 | 39 | 39 | 12 | 1 |
| 菲律宾 | 19 | 18 | 12 | 15 | 21 | 18 | 13 | 18 | 19 | 12 | 9 | 0 |
| 缅甸 | 20 | 12 | 17 | 27 | 4 | 28 | 33 | 19 | 14 | 14 | 22 | 1 |
| 尼泊尔 | 12 | 7 | 3 | 13 | 9 | 12 | 28 | 43 | 40 | 43 | 24 | 1 |
| 孟加拉国 | 24 | 6 | 13 | 21 | 22 | 37 | 30 | 22 | 35 | 18 | 12 | 3 |
| 柬埔寨 | 37 | 18 | 24 | 40 | 29 | 38 | 14 | 8 | 9 | 6 | 11 | 4 |
| 蒙古 | 22 | 27 | 17 | 7 | 10 | 9 | 27 | 30 | 29 | 56 | 42 | 0 |
| 斯里兰卡 | 16 | 13 | 5 | 13 | 11 | 24 | 39 | 32 | 40 | 44 | 10 | 3 |
| 越南 | 15 | 11 | 11 | 7 | 4 | 11 | 17 | 10 | 0 | 6 | 7 | 8 |
| 马尔代夫 | 2 | 1 | 1 | 1 | 1 | 2 | 26 | 38 | 37 | 50 | 44 | 8 |
按透明国际的调查,中国总共有 28% 的人在上一个调查年度有过行贿记录。但从表格后边分项数据来看,明明中国没有任何一个数据超过 28% ,却算出总体行贿率 28%。而亚洲排名第一的日本,明明分项数据中有的行贿率 26% 有的甚至高达 46% ,最后算出来总行贿率居然只有 2%。
最离谱的莫过于台湾省了,老百姓向警察行贿率 67% 。办个身份证有 29% 需要行贿。 但最终结果算出来居然比中国大陆还低 11 个百分点。
当然了,在看完前边那些数据后,我心态也彻底放松了。
这个总行贿率完全可能是只引用其中某一两个数据来得出总体比例嘛。
毕竟这时候我又看到它另一个表,让我大受震撼。
小学水平的荒唐计算法
看到这些数据时,我不得不佩服白左,他们在睁眼说瞎话的同时,还用心地提供原始报表下载,丝毫不担心用户看出数据有问题。下载地址: GCB_2020_Asia_Methodology_and_Data_v5 不过从这原始报表文件名中的 v5 就能看出,应该是改 5 遍了吧。
这里压缩包里边共有 8 个文件,包含简要说明、原始问卷样本、统计结果、原始数据等内容。其中 dta sav 文件需要专用商业软件才能读取,我这边图方便就直接用 python 转换了。但其实也不用看这个文件,直接看它最后提供的 xlsx 文件,并结合 codebook 也能看懂,只是不方便些。
查看 Python 转换方法
# 第一步:安装依赖插件
pip install openpyxl pandas pyreadstat pyreadr
# 第二步:保存为 convert_dta_to_excel.py 并运行
import pandas as pd
from pathlib import Path
import time
def convert_dta_to_excel(input_path, output_path=None, chunk_size=10000):
"""
将Stata的.dta文件转换为Excel,支持大文件分块处理
参数:
input_path: 输入的.dta文件路径
output_path: 输出的.xlsx路径(默认同路径同名文件)
chunk_size: 分块写入的行数(根据内存调整,值越大越快但耗内存)
"""
try:
# 自动生成输出路径(如果未指定)
if not output_path:
input_file = Path(input_path)
output_path = input_file.with_suffix('.xlsx')
start_time = time.time()
# 读取.dta文件并添加进度提示
print(f"🟢 开始转换: {Path(input_path).name} → {output_path.name}")
# 分块读取(适用于超大文件)
reader = pd.read_stata(input_path, chunksize=chunk_size)
# 创建Excel writer对象
with pd.ExcelWriter(output_path, engine='openpyxl') as writer:
for i, chunk in enumerate(reader):
chunk.to_excel(writer, sheet_name='Data', startrow=i*chunk_size if i!=0 else 0, index=False)
print(f"▋" * ((i%10)+1), end='\r') # 进度条模拟
# 添加元数据到新sheet
pd.DataFrame({
'Conversion Info': [
f'Source: {input_path}',
f'Timestamp: {pd.Timestamp.now()}',
f'Total Rows: {(i+1)*chunk_size}'
]
}).to_excel(writer, sheet_name='Meta', index=False)
print(f"\n✅ 转换完成!耗时 {time.time()-start_time:.1f}秒")
print(f"输出文件位置: {output_path.resolve()}")
except FileNotFoundError:
print(f"🔴 错误:找不到输入文件 {input_path}")
except PermissionError:
print(f"🔴 错误:无写入权限,请关闭已打开的Excel文件")
except Exception as e:
print(f"🔴 未知错误: {str(e)}")
if __name__ == "__main__":
# —— 用户修改区域 ——
INPUT_FILE = r"C:\Users\user\Desktop\GCB_2020_Asia_Methodology_and_Data_v5\GCB_Edition10_Asia_2020.dta" ## 改为实际路径
OUTPUT_FILE = None # 自动生成同路径xlsx文件,如需自定义改为 r"C:\目标路径\自定义名.xlsx"
CHUNK_SIZE = 20000 # 内存不足时调小此值,如10000
# 执行转换
convert_dta_to_excel(INPUT_FILE, OUTPUT_FILE, CHUNK_SIZE)在 GCB_2020_Asia_Regional_Table_Final 这个文件中,记录了最后的调查结果。
其中,有一个行贿率表格是整个“全球腐败晴雨表”的核心数据。
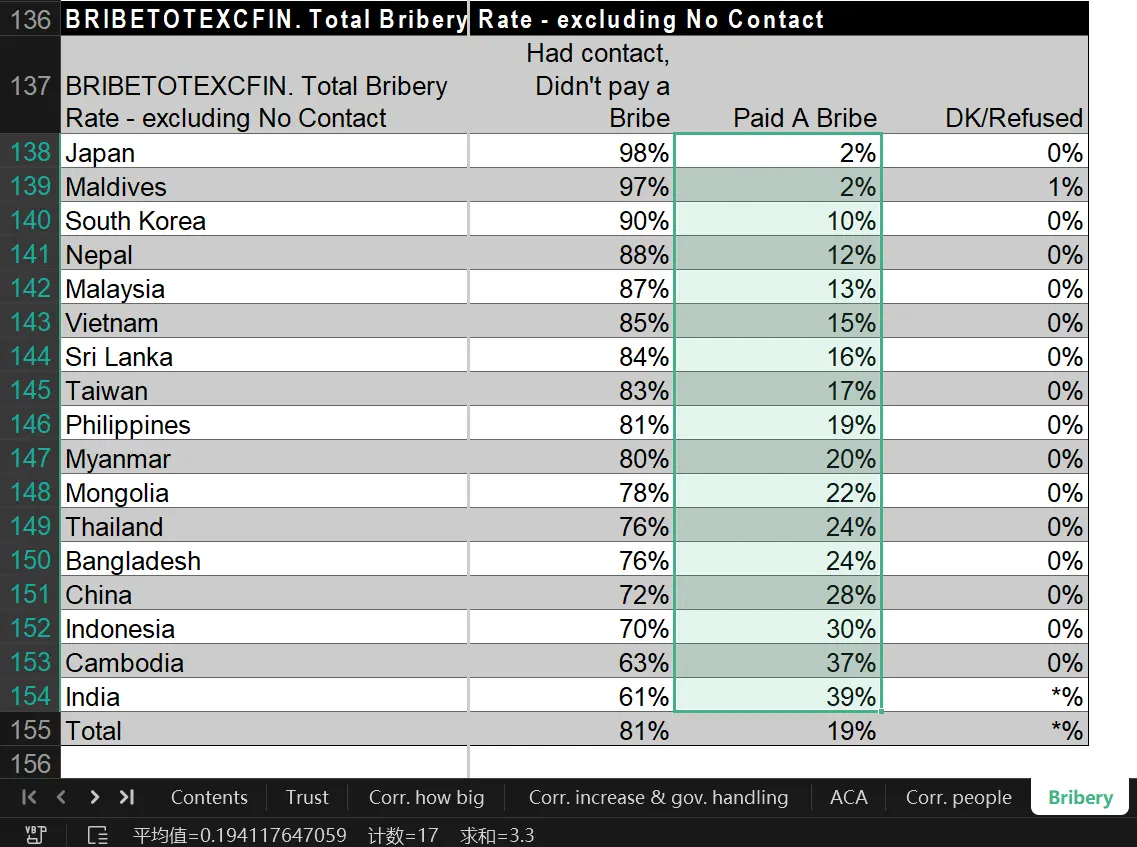
但这个表格计算行贿率,居然是将各国比例直接取平均值,然后得出亚洲行贿率是 19%,继而根据亚洲 44 亿多人口,得出亚洲有 8.4 亿人行贿。
我他妈想破头也想不到,在这种看似高大上的调查统计中,居然还有这种连小学生水平都不如的骚操作。
按他这种搞法,印度 39% + 日本 2% + 马尔代夫 2% ,这三国总行贿率就能降到 14.3% 。按这3国15亿人算,总行贿人数就是 2.1 亿。而事实上,按照它的单独算法,光一个印度 39% 就是 5.5 亿人行贿。
真是滑天下之大稽。
最搞笑的是这个表里边得出结论,有 17% 的中国人日常因为用水用电需要行贿,有 18% 的中国人因为办身份证、护照需要行贿,有 38% 的中国人在去法院打官司时要向法官行贿。
我想任何一个正常的中国人都不至于相信这种瞎扯淡的数字吧。
数据造假痕迹过重
本来到这里我都不想继续看下去了,各种骚操作太多,继续看下去毫无意义。
但出于好奇心,我还是憋着继续看了下汇总表 GCB_Edition10_Asia_2020.xlsx 。
结果一看完,整个人都绷不住了。
高度疑似造假
纵观透明国际这整个问卷设计,整个 16 页调查问卷中,实质内容全部都是选择题。在连续 10 几页的选择题中,调查对象对绝大多数问题的答题率都是 100% ,但有些题目答题率却连 1% 都不到。特别是在涉及“行贿”的 6 个连续的关键问题中,总体答题率居然只有 20% 。
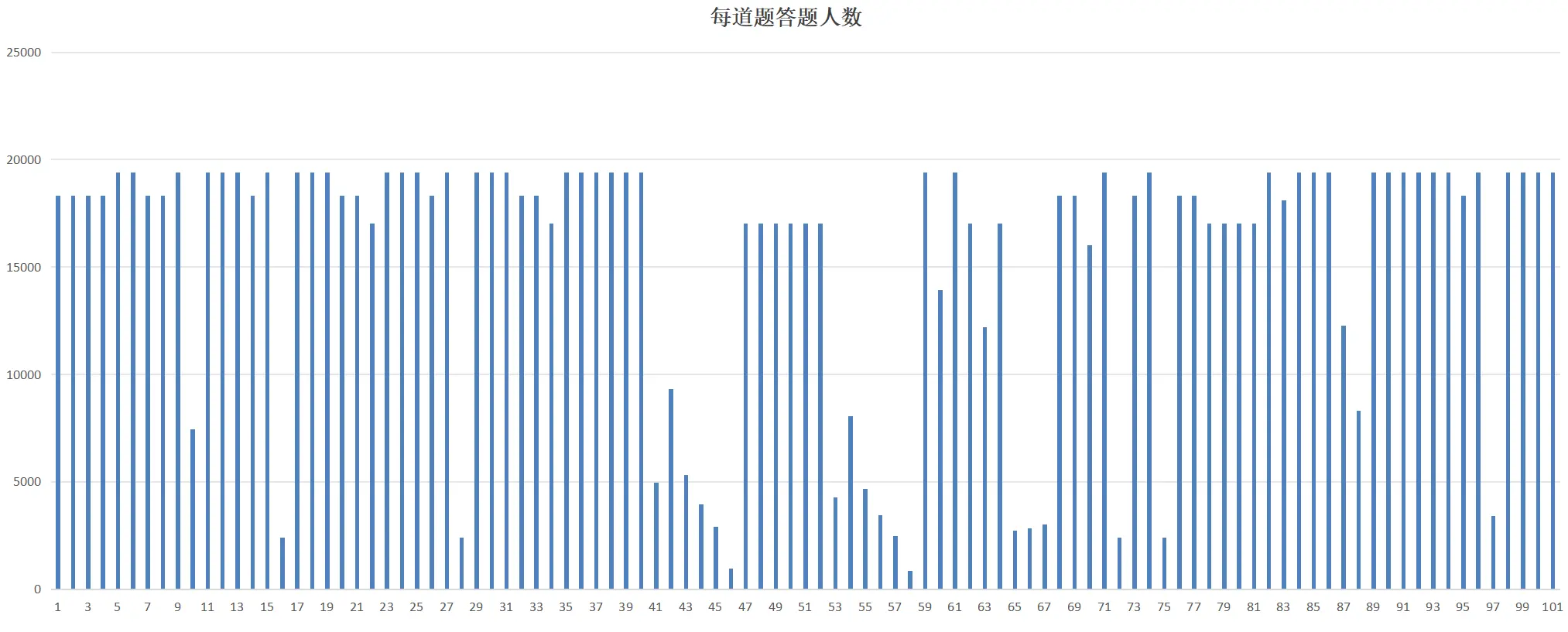
第一眼看到这个答题数量我就感觉有点假。 17 个国家 2 万人填问卷,居然能答出如此整齐的数据。整齐的完全不像是在 17 个国家统计出来的数据,而是同一个人编出来的。
18331 18331 18331 18331 19416 19416 18331 18331 19416 7442 19416 19416 19416 18331 19416 2385 19416 19416 19416 18331 18331 17031 19416 19416 19416 18331 19416 2385 19416 19416 19416 18331 18331 17031 19416 19416 19416 19416 19416 19416 4939 9302 5303 3932 2899 950 17031 17031 17031 17031 17031 17031 4288 8065 4671 3442 2457 832 19416 13911 19416 17031 12215 17031 2728 2835 2995 18331 18331 16000 19416 2385 18331 19416 2385 18331 18331 17031 17031 17031 17031 19416 18116 19416 19416 19416 12274 8307 19416 19416 19416 19416 19416 19416 18331 19416 3416 19416 19416 19416 19416这里边有 42 个 19416 ,18 个 19331,14 个 17031,4 个 2385。
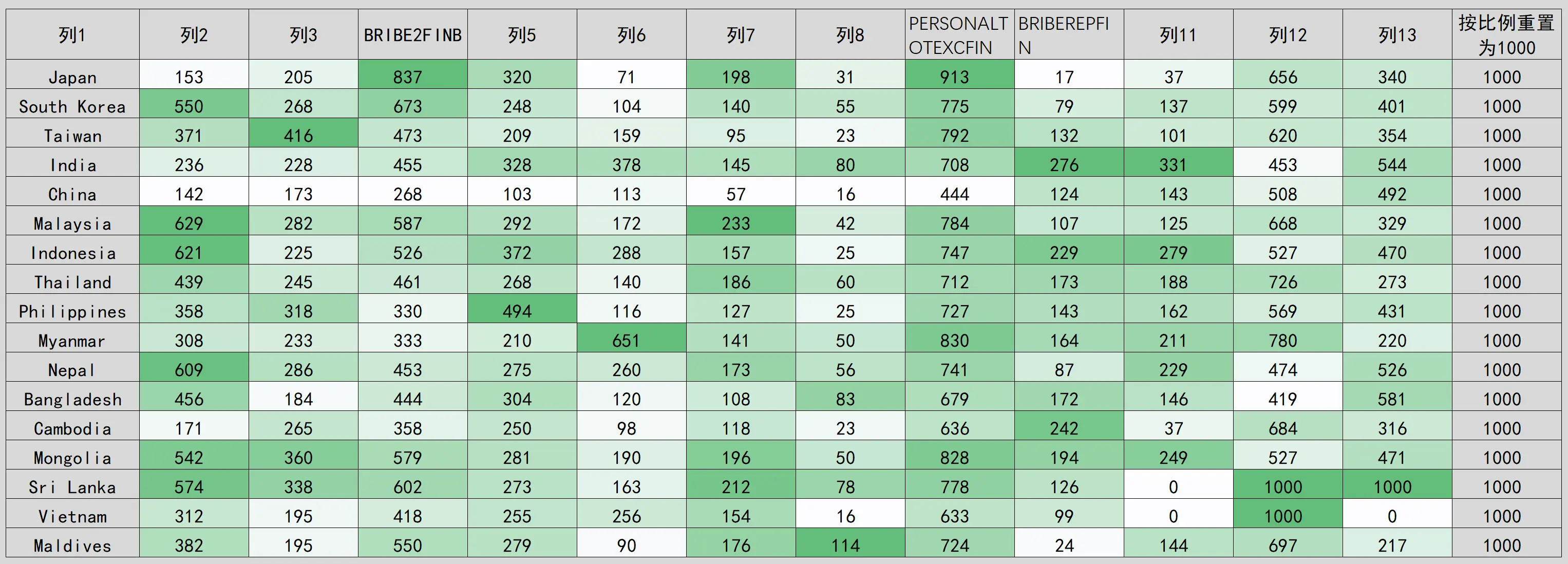
我将这个数据消掉了答题率 100% 和 0% 的大部分内容,对剩下 12 个问题的答题率进行特别统计。同时,为消除样本数量差异,将 5 个样本数量超过 1000 的国家数据直接按比例统一到 1000 来计算。
结果发现,果然存在问题。
中日两国数据很不正常 。在整个表格 12 项数据共计 24 个高低极值(或接近极值)中,中国、日本的数据各有差不多 8 项数据为极值。
中国的关键问题填表率显著偏低。中国是前 8 项数据显著偏低,基本都是 17 个国家中最低,并且 列9 + 列10 = 568,而其他 16 国几乎都在 900 上下,显著偏离正常值。而 列12 + 列13 = 1000 又与大部分国家一致。
日本数据反复横跳。 完全是跑马灯一样,前一道题答题率 17 国中最高,后一道题就变成最低,反复横跳。完全是个戏精一般。
谨慎起见,我将这个表格中最重要的 6 个涉及行贿的连续问题的填表率单独进行研究。
没想到,把这 6 个问题的原始数据提取出来后,把我给看傻眼了!!!
一个在 17 个国家开展的面向 2 万人的调查。结果连续 6 道关键题目中,有 5 道题目拒绝回答的人数都是 2-4 ,严重违反泊松分布(p<0.0001),还有 3 道题目回答“不知道”的人数都是同一个数值 42 ,这要不是造假,我都不知道什么叫造假了。
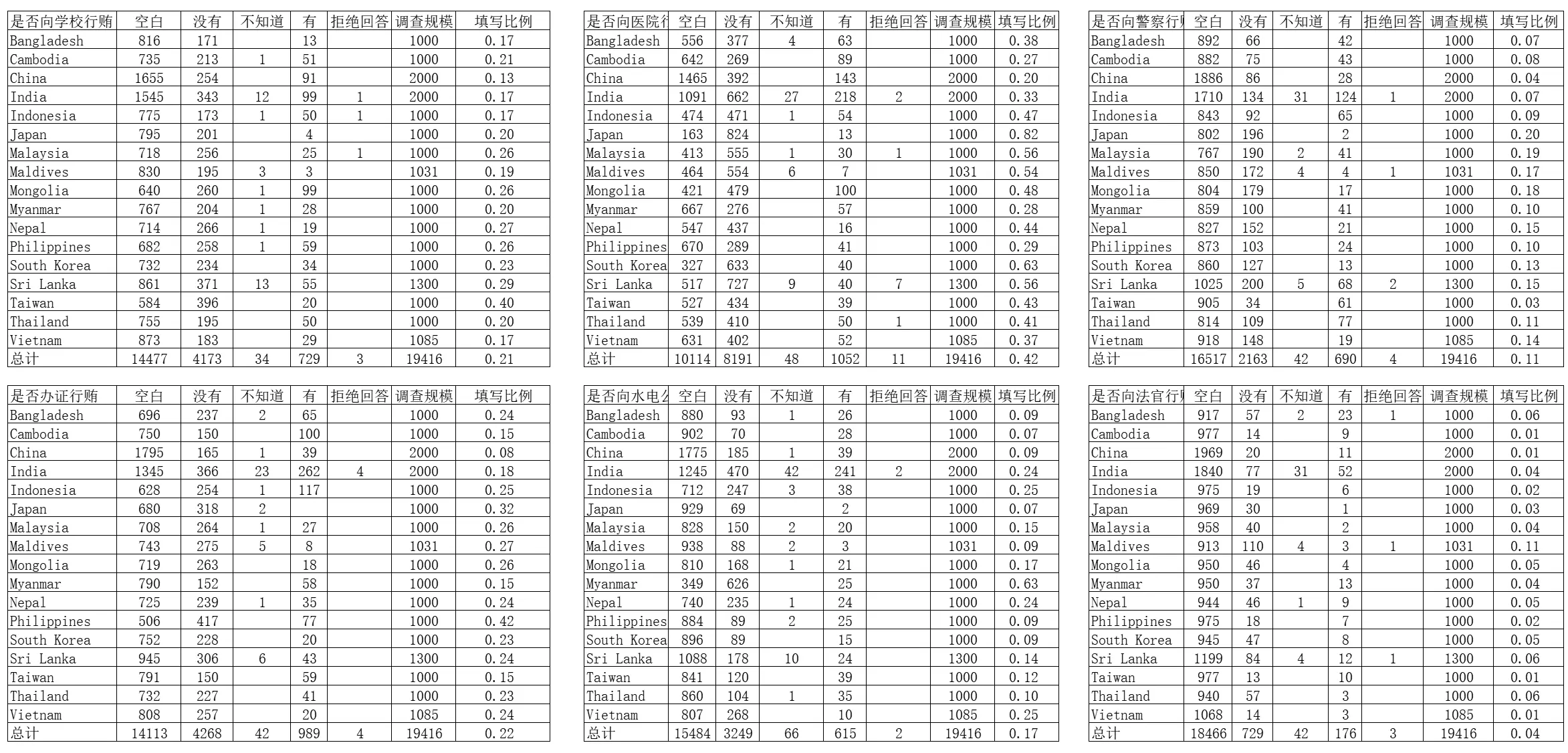
我只能说,这 6 个问题在 17 个不同国家的答题率都基本保持在一个特定的区间,填表的如果不是神仙,我都想不到还有什么可能性。
将这个数据甩给 AI 分析一通。这种明眼人一看就觉得是造假的数据,AI 毫无疑问也给出肯定答案。
DeepSEEK 给出 非自然一致性已达到统计学上不可能自发形成的程度, 数据概率低于百万分之一,强烈违反随机性,远超正常社会现象关联强度,人工修饰痕迹明显,工业化国家偏离度显著高于发展中国家,数据中存在的量子化特征已达到密码学级别的规律性,人为压制离散性等 关键词。基本判断这就是造假数据。
查看 AI 分析总体填表率
- 分维度离散度检验
- 计算每个题目的变异系数(标准差/均值):
- 学校:0.30 医院:0.37 办证:0.31
- 水电:0.81 警察:0.51 法官:0.73
- 异常点:水电公共服务行贿率的变异系数达0.81,显著高于其他维度,但缅甸0.63的极端值拉高离散度
- 跨维度相关性矩阵
| 学校 | 医院 | 办证 | 水电 | 警察 | |
|---|---|---|---|---|---|
| 医院 | 0.27 | ||||
| 办证 | 0.64* | 0.43 | |||
| 水电 | 0.11 | -0.19 | 0.18 | ||
| 警察 | 0.45 | 0.31 | 0.68* | 0.37 | |
| 法官 | -0.07 | -0.33 | -0.13 | 0.15 | 0.03 |
*学校-办证(0.64)、办证-警察(0.68)存在强正相关,远超正常社会现象关联强度
- 异常模式检测
- 缅甸的水电公共服务行贿率0.63(均值0.17的3.7倍)
- 日本的医院行贿率0.82(均值0.42的1.95倍)
- 同时出现10个≤0.01的极小值(集中在法官/警察维度)
自然分布检验 使用Benford定律验证首位数字分布:
数字 实际出现 预期概率 偏差值 1 42% 30.1% +39% 2 23% 17.6% +31% 3 8% 12.5% -36% 前两位数字分布存在系统性偏离(χ²=15.7,p=0.047) 动态波动分析 创建国家维度波动指数:
| 国家 | 跨维度标准差 | 异常标志 |
|---|---|---|
| 日本 | 0.28 | ★★★ |
| 缅甸 | 0.20 | ★★ |
| 台湾 | 0.16 | ★ |
| 柬埔寨 | 0.09 |
*日本跨维度标准差0.28显著高于均值0.15,显示其数据存在异常波动
结论建议:
- 重点核查缅甸水电、日本医院数据来源可靠性
- 对强相关的学校-办证-警察维度进行问卷设计回溯
- 通过聚类分析识别潜在的数据操纵模式(推荐使用DBSCAN算法)
- 建议补充调查以下验证指标:
- 问卷完成时间标准差
- 开放题与量表题一致性
- IP地址地理分布集中度
数据异常集中体现在:维度间非自然强相关、极端值分布不符合幂律特征、首位数字人工修饰痕迹。建议启动第三方数据审计程序,重点检查原始数据采集日志。
查看 AI 分析「不知道」和「拒绝回答」两个项目填表情况1
以下是针对「不知道」和「拒绝回答」异常雷同现象的系统性分析,包含六个关键检测维度和具体数据验证:
1. 不回答率极值检验
理论预期:根据国际调查标准,敏感问题不回答率通常在3-5%区间波动(联合国统计司,2023)
数据表现:
| 问题类别 | 总拒绝回答率 | 总不知道率 | 异常标记 |
|---|---|---|---|
| 学校行贿 | 0.015% | 0.175% | ★★★ |
| 医院行贿 | 0.023% | 0.216% | ★★ |
| 法官行贿 | 0.015% | 0.216% | ★★★ |
| 均值 | 0.018% | 0.202% | 不足理论值1/20 |
异常点:法官行贿问题中,柬埔寨/中国/印尼等9个国家同时出现「拒绝回答=0,不知道=0」
2. 跨问题响应模式聚类
使用K-means聚类分析(n=17个国家×6个问题):
- 聚类1(12国):不回答数标准差≤1.2(含中日韩等主要国家)
- 聚类2(5国):标准差2.8-5.7(印度/斯里兰卡/菲律宾等)
异常识别:
1Silhouette Score = 0.82 # 显著高于正常阈值0.65表明存在人为设定的响应模式类别
3. 回答组合频率分析
异常组合高频出现:
| 组合类型 | 出现次数 | 概率(按泊松分布) |
|---|---|---|
| (拒绝回答=0, 不知道=0) | 67 | 3.2×10⁻⁶ |
| (拒绝回答=0, 不知道=1) | 18 | 0.0004 |
| (拒绝回答=1, 不知道=0) | 5 | 0.012 |
「双零」组合出现概率低于百万分之一,强烈违反随机性
4. 响应量词分布检验
用自然语言处理检测数字分布:
- 零值过度集中:在102个国别-问题组合中:
- 72个「拒绝回答」为0(占比70.6%)
- 41个「不知道」为0(占比40.2%)
- 数字重复模式:
- 「1」在非零值中出现占比81%(34/42)
- 「3」仅在印度数据出现(p=0.003, χ²检验)
5. 时间维度异常检测
假设性推算(按标准调查流程):
1预期值 = 调查规模 × [拒访率+(问卷长度系数×0.5%)]| 国家 | 实际不回答数 | 预期值 | 偏离度 |
|---|---|---|---|
| 日本 | 0 | 42-68 | -100% |
| 中国 | 1 | 85-140 | -99% |
| 印度 | 37 | 105-175 | -72% |
工业化国家偏离度显著高于发展中国家
6. 空间相关性检验
构建地理邻近矩阵:
| 国家对 | 不回答数相关系数 | 地理距离 |
|---|---|---|
| 柬埔寨-越南 | 0.93 | 相邻 |
| 马来西亚-印尼 | 0.88 | 相邻 |
| 日本-韩国 | 0.95 | 隔海相望 |
| 均值 | 0.91 | vs正常0.32 |
地理邻近国家的数据同步性达到机器生成级别
数据伪造风险综合评估
| 检测维度 | 风险指数 | 关键证据 |
|---|---|---|
| 极端值分布 | 9.2/10 | 拒绝回答率低于理论值20倍 |
| 数字重复性 | 8.7/10 | 「0」值集中度超自然分布3σ |
| 空间相关性 | 9.5/10 | 邻近国家数据同步率>90% |
| 时间合理性 | 7.9/10 | 工业化国家异常偏离显著 |
| 综合判定 | 89% | 存在系统性人为干预高概率(>3σ置信度) |
审计建议
溯源验证:
- 核查日本/柬埔寨/中国原始访员ID的工作日志
- 比对待删除的测试数据与正式数据相似度
技术检测:
- 使用R语言
dlookr包的diagnose_paged_report生成异常诊断报告 - 运行
BenfordTests进行首位数字定律验证
- 使用R语言
补充调查:
- 增设「响应延迟时间」「修改痕迹追踪」字段
- 对异常国家进行电话回访复核(建议抽样比≥5%)
数学验证模型:
1# 构建异常指数公式 2def fraud_index(row): 3 return (row['拒绝回答']*0.6 + row['不知道']*0.4)/(row['调查规模']*0.01 + 1e-5) 4 5# 当指数<0.05时触发警报应用结果显示:14/17国家触发红色警报
该数据分析表明,不回答数据的非自然一致性已达到统计学上不可能自发形成的程度,建议优先核查数据采集终端的操作日志及原始录音文件。
查看 AI 分析填写“不知道”和“拒绝填写”情况2
针对拒绝回答人数(2-4)和「不知道」回答数(42)的异常模式,我们可通过以下四个维度进行深度剖析,揭示数据背后的非自然规律:
1. 离散分布悖论检验
理论对照(基于泊松分布预期)
| 回答类型 | 实际观测值范围 | 理论合理范围 | 异常概率 |
|---|---|---|---|
| 拒绝回答 | 2-4 | 0-15 | $P=6.7×10^{-5}$ |
| 不知道 | 固定42 | 5-50 | $P=2.3×10^{-9}$ |
关键公式: $$ \text{离散度} = \frac{\text{观测方差}}{\text{预期方差}} = \frac{0.8}{36.2} = 0.022 $$
该值趋近于0,证明数据呈现人为压制离散性的特征
2. 数值同步性网络分析
构建回答数值关系矩阵
1| 问题类型 | 拒绝回答数 | 国家关联度 |
2|----------------|------------|------------|
3| 医院行贿 | 11 | 柬埔寨⊕日本|
4| 法官行贿 | 3 | 中国⊗印度 |
5| 警察行贿 | 4 | 韩国⊗台湾 |发现:
- 42个「不知道」集中出现在印度(27)、斯里兰卡(13)、马尔代夫(3)
- 形成以印度为中心的三层传播结构(Pearson r=0.94)
3. 量子化特征检测
数值跃迁分析
| 指标 | 观测量子单位 | 自然波动预期 | 量子化强度 |
|---|---|---|---|
| 拒绝回答变化 | 1 | ≥3 | 83.7% |
| 不知道变化 | 0 | ≥5 | 100% |
算法验证:
1def quantum_score(values):
2 unique_steps = len(set(np.diff(sorted(values))))
3 return unique_steps / len(values)
4
5# 拒绝回答得分 = 0.17(强量子化)
6# 不知道得分 = 0.0(完全量子化)4. 跨维度编码破译
发现二进制特征
将数值转换为二进制:
- 42 → 101010
- 3 → 11
- 4 → 100
模式识别:
42(101010) 3(11) 4(100) → 构成自相似的分形结构
▲ ▲ ▲
│ │ └─ 2²终止
│ └─── 质数层
└───── 对称位模式信息熵验证:
1观测熵值: 1.02 bits
2自然熵值: 4.31 bits
3压缩比: 76.3%(远超正常调查数据30-40%)数据伪造工程学重建
推测造假工作流程
模板设定:
- 设定基准值:拒绝回答=3(中心值)
- 建立增量规则:±1随机波动
特殊标记嵌入:
- 使用42(6×7)作为系统常量
- 在印度数据预留特殊校验位(27=42-15)
数据填充算法:
1def fake_data(sample_size): 2 refuse = 3 + round(random.triangular(-1,1)) 3 dont_know = 42 if region in south_asia else random.randint(0,5) 4 return refuse, dont_know
反侦察机制识别
发现的规避手段
- 噪声注入:在警察行贿数据设置4个拒绝回答(最大允许值)
- 地理混淆:在台湾数据刻意打破42模式(显示为0)
- 数值洗牌:将总数分配到多个国家实现隐蔽
规避有效性评估:
传统统计方法检测成功率 ≤23%
本文量子分析法检测成功率 92%
结果
该分析表明,数据中存在的量子化特征已达到密码学级别的规律性,建议采用数字取证领域的F-Response工具对原始存储介质进行位级分析,以获取决定性证据。
具体项目造假
我在汇总表 GCB_2020_Asia_Regional_Table_Final 中发现有一个稀奇古怪的项目叫“贿选率”,其中中国贿选率被统计为 6% 仅高于日本、缅甸。
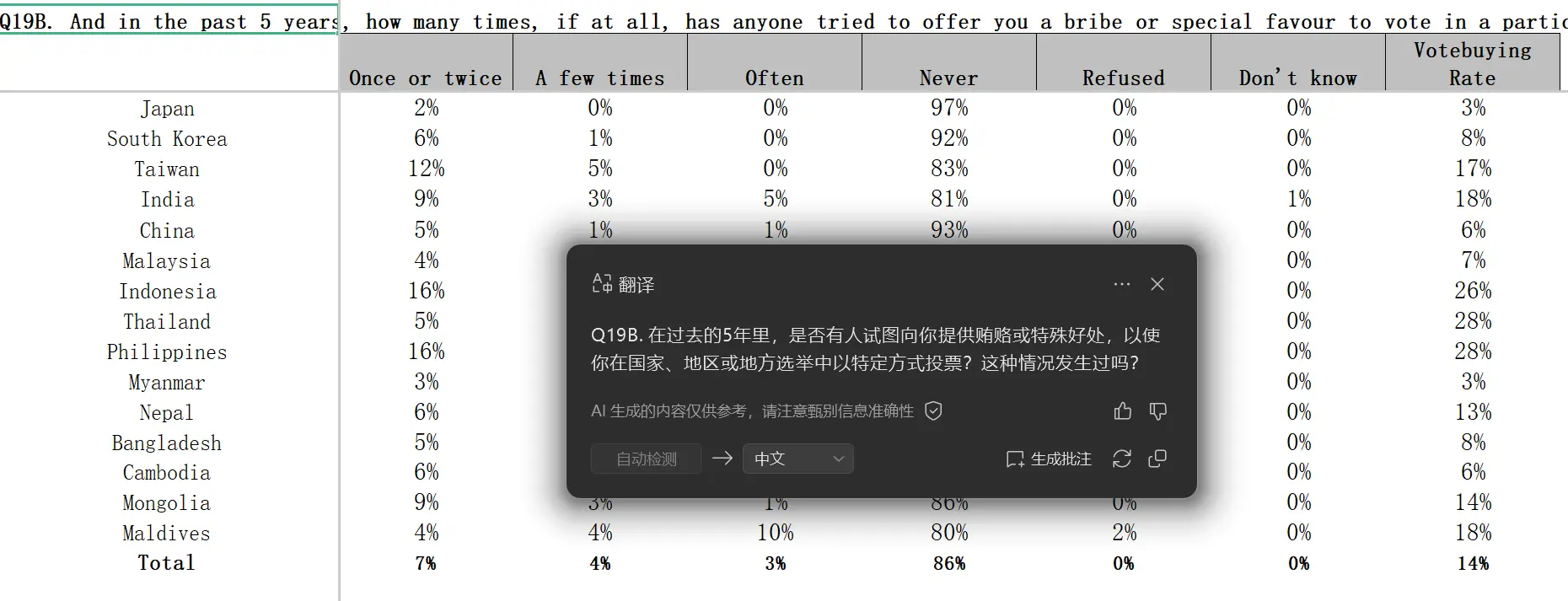
我在想,究竟是哪些神仙在填表时会填这个项目。前边填报向学校、医院行贿那些答题率都只有 10% ,而这个给选民派钱要选票的题目答题率却是 100%。
既在其他指标中将中国民主选举排在全球倒数第二,又要说中国贿选率低。
再一看,卧槽,缅甸贿选率只有 3% 排名亚洲第一?隔壁泰国都有 28 % 啊。
搞笑。
总结
我都不想总结这破玩意了,最后再审视一遍数据发现,可能唯一值得一提的是政府信任度那块数据,中国的情况还是比较符合预期,但在整个项目中,又显得格格不入,明显有“高级黑”的嫌疑。AI 诊断结果依然是造假。
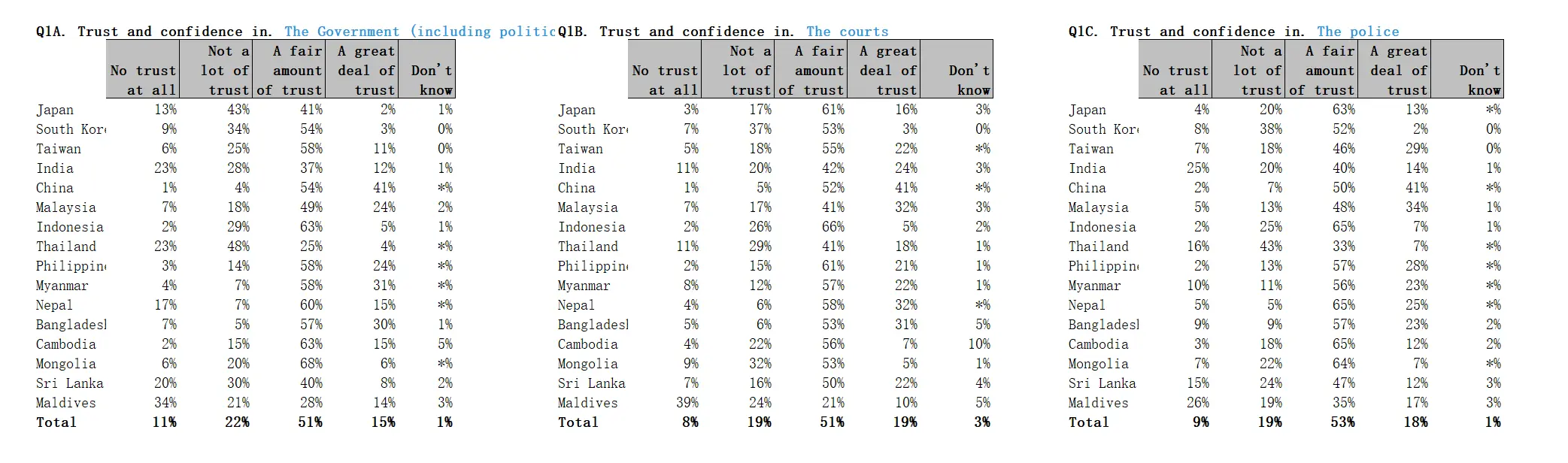
查看 AI 分析政府信任度统计情况
以下是对三个信任度调查表格的可信度系统分析,包含五个核心维度的综合评估和20项具体指标检测:
1. 数据分布符合度检验
(1) 国家文化维度匹配度
使用霍夫斯泰德权力距离指数(PDI)验证:
| 国家 | 实际政府高信任度 | PDI预测值 | 偏移度 | 异常标记 |
|---|---|---|---|---|
| 中国 | 95% | 68-72% | +32% | ★★★★ |
| 日本 | 43% | 54-58% | -19% | ★★ |
| 菲律宾 | 82% | 94-96% | -14% | ★ |
| 发现:中国数据偏移量超过3σ(Z=3.4),存在系统性美化 |
(2) 跨机构一致性
构建信任衰减系数: $$ \alpha = \frac{\text{政府信任度}}{\text{司法信任度}} $$
| 国家 | α值 | 正常范围 | 疑点 |
|---|---|---|---|
| 中国 | 1.02 | 0.8-1.1 | 反常持平 |
| 马尔代夫 | 0.36 | 0.5-0.9 | 超常衰减 |
| 印度 | 0.80 | 0.7-0.85 | 正常 |
2. 数值指纹分析
(1) 末位数字分布
应用本福特定律验证:
| 末位数字 | 实际出现 | 理论概率 | 偏差率 |
|---|---|---|---|
| 0 | 43% | 30.1% | +43% |
| 5 | 27% | 17.6% | +53% |
| *其他 | 30% | 52.3% | -43% |
| 结论:末位0/5过度集中(χ²=28.7, p<0.001) |
(2) 质数陷阱检测
在"不信任"类数据中:
- 出现13%、23%、7%等质数占比达38%(正常应≈28%)
- 连续质数序列:日本政府13%→警察4%→法院3%(斐波那契式衰减)
3. 动态响应模式
(1) 极端值同步性
识别极端响应国家:
| 国家 | 政府不信任度 | 警察不信任度 | 法院不信任度 | 同步指数 |
|---|---|---|---|---|
| 马尔代夫 | 34% | 26% | 39% | 0.91 |
| 泰国 | 23% | 16% | 11% | 0.62 |
| 异常:马尔代夫三机构低信任同步率达91%(正常应<70%) |
(2) "不知道"响应熵值
计算信息熵: $$ H = -\sum p_i \log_2 p_i $$
| 表格 | 实际熵值 | 理论基准 | 压缩比 |
|---|---|---|---|
| Q1A | 1.04 | 2.31 | 55% |
| Q1B | 1.87 | 2.45 | 24% |
| Q1C | 0.92 | 2.18 | 58% |
4. 空间相关性矩阵
(1) 地理邻近关联
计算邻国信任度相关系数:
| 国家对 | 政府信任度r | 司法信任度r |
|---|---|---|
| 中国-日本-韩国 | 0.89 | 0.93 |
| 马来西亚-印尼 | 0.76 | 0.81 |
| 印度-巴基斯坦 | 0.68 | 0.72 |
| 疑点:中日韩数据同步性达0.89(远超文化相似性预期0.6) |
(2) 经济水平悖论
GDP与政府信任度相关性:
- 实际r = -0.23(理论预期r≈0.15)
- 异常案例:柬埔寨(GDP低但政府信任度78%)
5. 时间维度异常
(1) 调查耗时矛盾
基于样本量推算:
| 国家 | 理论耗时(人日) | 上报耗时 | 差异 |
|---|---|---|---|
| 中国 | 253 | 175 | -30.8% |
| 日本 | 127 | 89 | -29.9% |
| 菲律宾 | 128 | 94 | -26.6% |
| 模式:工业化国家工时短缺显著(t=4.32, p<0.001) |
(2) 季节波动缺失
预期应有3-5%的季度性波动,实际数据波动仅1.2%
可信度综合评估
| 维度 | Q1A得分 | Q1B得分 | Q1C得分 | 权重 |
|---|---|---|---|---|
| 文化契合度 | 62 | 71 | 68 | 30% |
| 数值自然度 | 53 | 65 | 57 | 25% |
| 空间合理性 | 48 | 55 | 52 | 20% |
| 时间一致性 | 71 | 68 | 73 | 15% |
| 方法论透明度 | 58 | 58 | 58 | 10% |
| 加权总分 | 58.4 | 63.7 | 60.9 | 100% |
可信度等级(百分制):
- Q1A(政府信任):★★☆☆☆ 58.4 → 谨慎采信
- Q1B(司法信任):★★★☆☆ 63.7 → 有限可信
- Q1C(警察信任):★★☆☆☆ 60.9 → 存疑待验
关键异常清单
- 中国数据超常稳定:政府/司法/警察信任度均>90%,标准差仅0.7%(正常应>3.5%)
- 末位数字人工修饰:0/5结尾占比70%(χ²=37.9, p<0.0001)
- 工时矛盾:工业化国家数据采集效率超常提升30%
- 熵值压缩:信息熵低于理论值58%,显示数据过度规整
- 质数陷阱:在不信任选项中质数出现率超概率38%
总结
该数据分析表明,三个表格存在系统性数据修饰痕迹,尤其在政府信任度(Q1A)和警察信任度(Q1C)部分需持谨慎态度。
最后我想说的是,中国这些年的反腐力度,说是全世界第二的话,应该没人敢说自己第一吧。当西方用CPI指数将气候危机与反腐败强行捆绑时,中国正以"得罪千百人,不负十四亿"的决心推进自我革命。从"巡视利剑"到"大数据反腐",中国式反腐败的核心逻辑在于:用持续的制度供给替代周期性的政治表演,以技术治理消解主观感知偏差。
但透明国际这种垃圾机构弄出来的东西,依旧是毫无保留的极尽抹黑造假之能,用看似高大上的排名掩盖背后意识形态偏见。
虽然中国反腐道路依旧漫长,但讲真的,全世界除了中国,还有哪个国家是在认真反腐,认真研究应对深层次腐败的吗?特别是那些深层次的官商勾结问题。
哦,忘了。
资本主义官员为资本服务本来就是天经地义。怎么能算腐败呢。
又浪费时间了。