小型纯 CPU 环境的中文命名实体识别模型选择

最近我在开发一款智能案例分析应用,因本地没有合适的模型能够达成分析效果,只能借助远程全量大模型来分析。但这过程中,如何保障数据安全则是一个非常重要的话题。我的初步设想是,在提交远程分析之前,先在本地做数据脱敏,并且在数据脱敏前,绝不能上云。由此,我开始了一段漫长测试。
小模型的效率和精度取舍
起初,我追求极致的轻量化,尝试了 20MB 左右的纯前端小模型 ,比如 ckiplab-bert-tiny-chinese-ner 以及更加精简的 ckiplab-albert-tiny-chinese-ner。用起来确实爽,我在用 100 条测试数据进行批量抽取时发现,这种小模型在 PC 上几乎是几秒钟就处理完了。只是处理精度略显不足,在数据正文中很多人名、机构名并没有被准确识别;而且一些三字人名被同时识别成了两个人。特别是面对一些口语化表达的案例时,很多口语化的实体名字,也都无法识别出来。
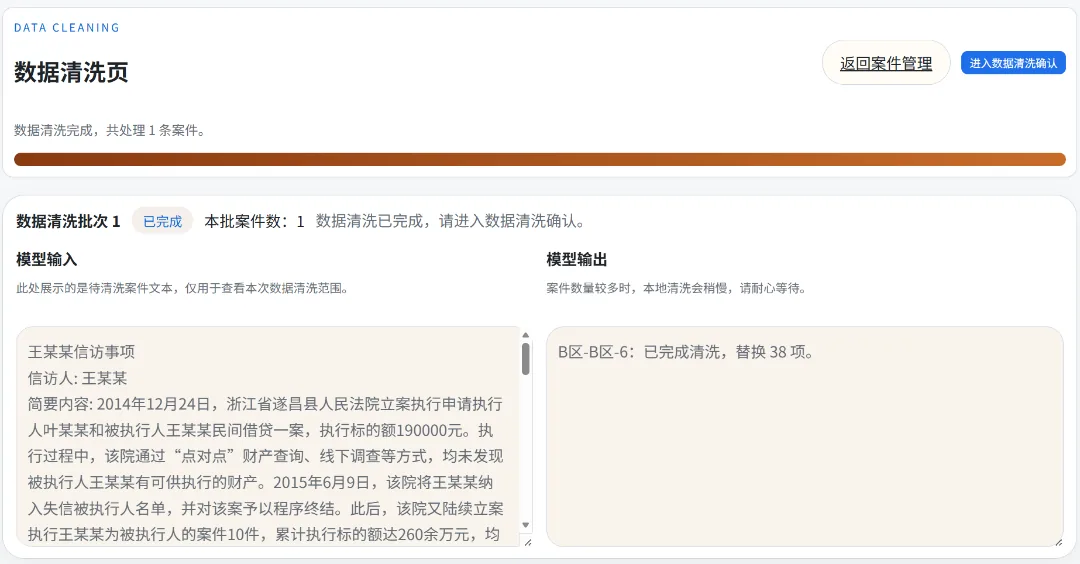
当然,我在设计这个应用过程中,本就考虑到这种情况,所以添加了一个非常人性化的人工审校机制。将前边脱敏后的数据,打碎成一个一个的汉字,点选未能完成的脱敏词汇即可自动补充进脱敏数据库。
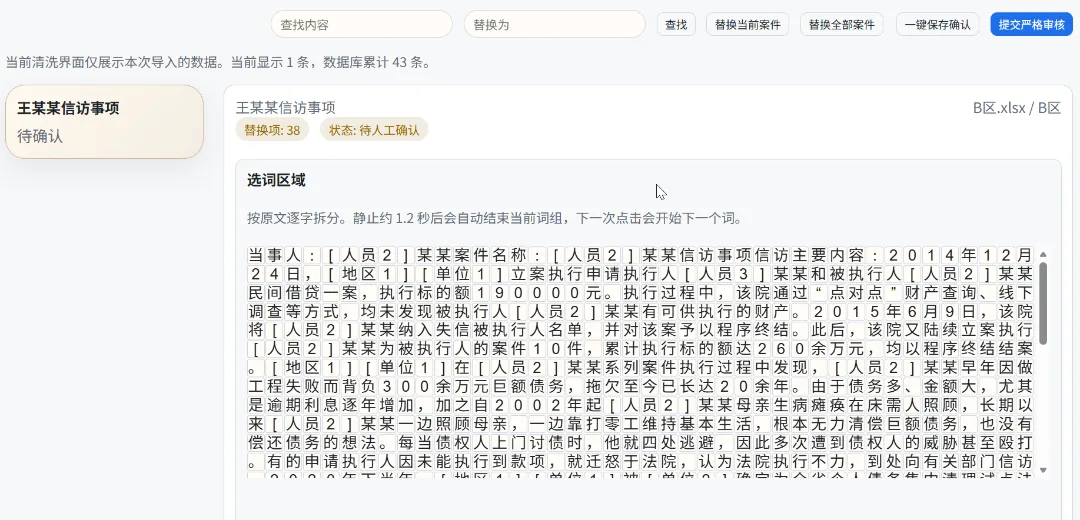
但小模型处理效率确实不高,我实测可能有接近 30% 的人名以及简写地名、公司名未能识别出来。特别是案例中提到的一些地区简称、单位缩写,这类 NER 模型拿着几乎无法识别。而一次性替换这些字、词,很容易导致正文语义错乱。手工操作起来也很头疼。
大模型对硬件考验压力很大
随后,我转向了最近风很大的“小参数大模型”,也就是 Qwen3.5:0.8B ,作为对比,也同时拉了去年的 DeepSeek-R1:1.5B 测试。毕竟,在纯 CPU 环境下,这已经是我能忍受的极限尺寸。我本以为大模型的语义理解能通杀一切,结果在实体抽取任务中,它们表现得极其不稳定。不仅逻辑门槛迈不过去,长文本也极易丢失命令,唯一好点的是,在关闭 Qwen 的 think 模式后,吐字终于算是恢复正常,但每轮测试时,出来的数据都很不稳定。
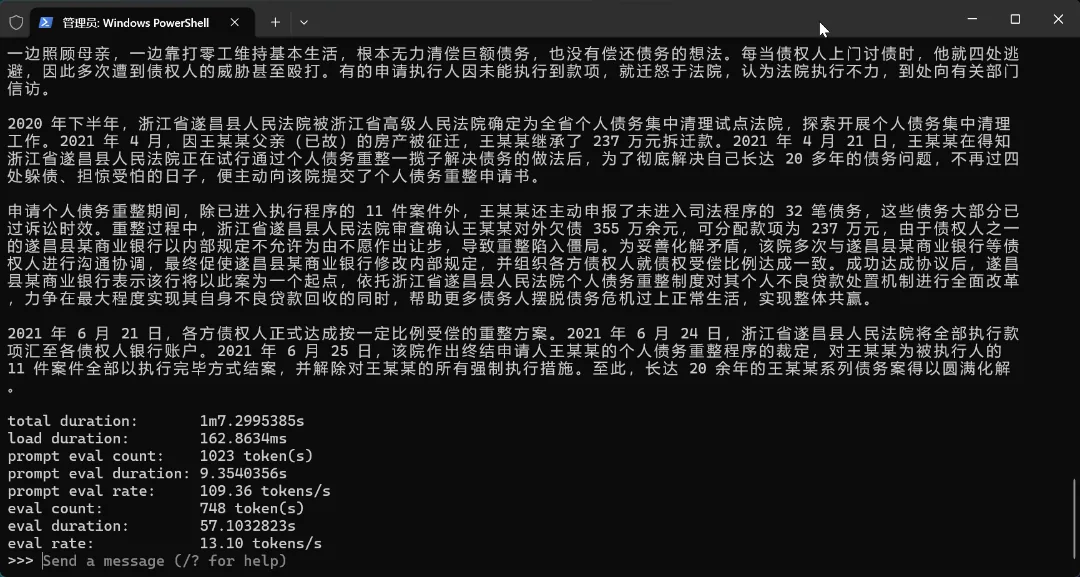
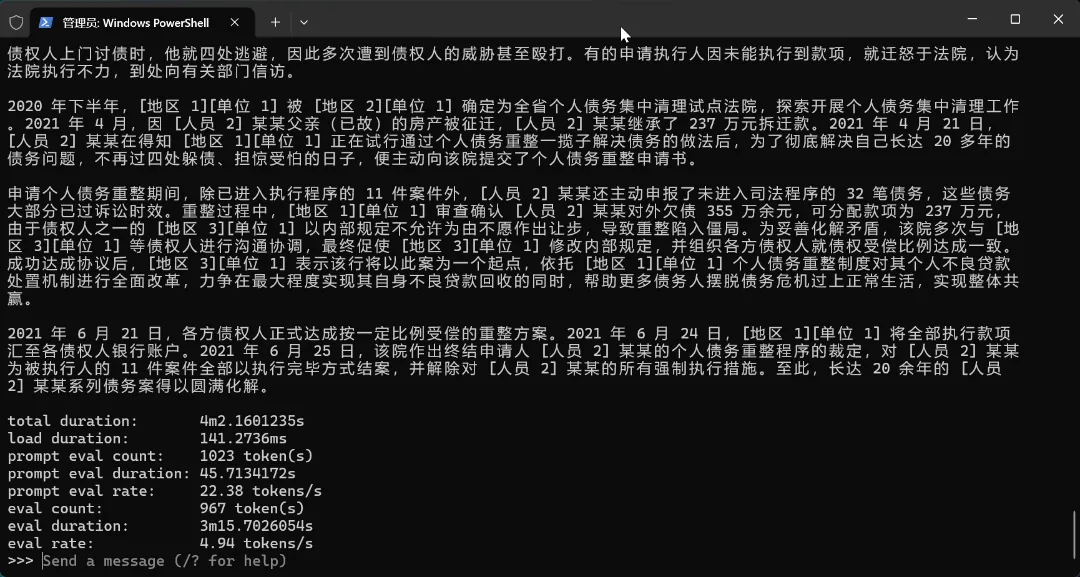
但过程中也不是没有收获,我不死心的用 Qwen3.5:4B 进行了测试,结果发现 4B 模型对我这种长文本的脱敏需求,效果非常好,几乎可以看成是与 0.8B 完全两个不同的模型。只是,在我测试所用笔记本电脑上,Ollama 版 Qwen3.5:4b 的吐字效率仅有 5 tokens/s ,即便换成 gguf 版本,也只能到 7 tokens/s,用起来还是很难受的,一条 100 字以内数据都要 2 分钟。
| 指标 | Ollama (标准版) | Unsloth GGUF | 优胜者 |
|---|---|---|---|
| Prompt 预处理速度 (Prefill) | 77.38 tok/s | 27.5 tok/s | Ollama (快 2.8 倍) |
| 文本生成速度 (Decode) | 5.53 tok/s | 8.6 tok/s | Unsloth (快 1.5 倍) |
| 总耗时 (Total) | 163.5s | 119.4s | Unsloth (节省约 44s) |
| 输入 Token 数 | 754 | 778 | - |
| 生成 Token 数 | 847 | 779 | - |
中等 NER 模型在性能和效率上总体比较平衡
在开发这个项目过程中,我还对比测试了 RaNER、HanLP、SpaCy、Siamese-UniNLU 等方案。过程中没有留下详尽的对比数据,但主观实测后似乎没有一个能满足我的需求。比如 RaNER 一开始就是在长文本时出现问题,Siamese-UniNLU 也是败在长文本上。SpaCy 和 HanLP 则是在文字截断上反复出现问题,对于一些实体名称的判断,经常与前后字符扯在一起。
在反复折腾中,最后我选择了两套看起来在性能和效果上比较平衡的方案:
纯本地 CPU 环境,使用 RaNER 与 REX-UniNLU
在折腾了一圈后,我最终回过头来死磕阿里系的两个专项模型:RaNER 和 REX-UniNLU。
RaNER (Base-Generic) 本来是我第一个下载的模型,但是他对长文本处理存在很大短板,默认只能支持 512 Tokens,但是放眼中文圈,各种评测数据都显示 RaNER 的效果是最强的,400MB 的通用 Base 版对人名、地名和机构的识别精度可以达到 91%。虽然我在测试时,发现其在法律领域可能达不到这么高比例,但考虑到我最终的应用方案是“NER 脱敏 + 人工确认 + 护栏审查”方式,实际上只需要两套不同逻辑的 NER 模型即可实现更高的精度。
REX-UniNLU (DeBERTa-v3) 是我在测试 Siamese-UniNLU 时偶然发现的,应该是作为 Siamese 的替代项目,并且原生更好地解决了长文本输入问题。但由于这个模型也是个 400M 的通用模型,它不仅能干 NER 的活,而且能搞关系、事实和情感抽取,所以放在后边当数据护栏审核其实相当不错。它对口语化表达和复杂嵌套实体的捕捉非常敏锐,很好地补全了传统 NER 模型在边界判定上的死板。并且,在这过程中,我引入的是最严格的实体抽取模式,它几乎能把所有“涉嫌”实体的名称都给抽取出来。
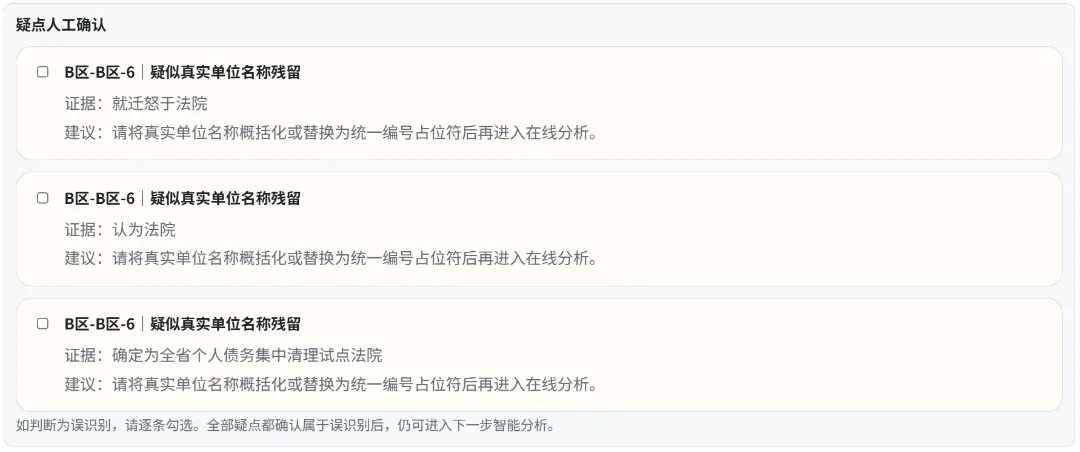
在线 VPS 环境,使用 ckiplab-albert-tiny-chinese-ner 与 SpaCy
如果说 RaNER + REX 是为了在 16G 内存的 PC 上追求极致精度,那么当我把视野转向 4G 内存的群晖 NAS,或者只有 1 核 2G 的便宜 VPS 时,这套“重装甲”就跑不动了。在这种极限环境下,我最喜欢的组合是 ckiplab-bert-tiny-chinese-ner 配合 SpaCy。
ckiplab-albert-tiny 只有不到 15MB,它的作用是利用 BERT 的残余语义能力,在毫秒级时间内把文本中那些最明显的、格式规范的人名和地名先“洗”一遍。虽然它会漏掉复杂的口语表达,但它极低的算力消耗为后续流程腾出了空间。
紧接着,我引入了 SpaCy (zh_core_web_md)。SpaCy 的优势不在于它有多“聪明”,而在于它极高的工业稳定性。作为一套基于 Cython 实现的 NLP 框架,它在处理行政区划和基础机构名时表现得非常稳健。把这两个模型串联起来,一个负责快速冲锋,一个负责守底线,再加上我的“人机审校”逻辑,在低功耗环境下依然能构筑起一道坚实的数据安全护栏。